大家好,我是极客老墨。
为什么 Go 语言能轻松支撑百万并发?为什么 Goroutine 切换成本这么低?这一切的背后,都站着一位神秘的大管家——GMP 调度器。这篇就用通俗易懂的语言,配合生动的比喻,带你深入理解 Go 高并发的核心秘密。
1. 为什么需要 GMP?
在很久很久以前(其实也就几十年前),我们写代码都是直接跟 线程 (Thread) 打交道。线程是操作系统(OS)调度的最小单位。
但是,线程这玩意儿太"贵"了:
- 内存占用高:一个线程栈大概要几 MB。
- 切换成本大:线程切换需要陷入内核态,保存寄存器、上下文,这简直就是"劳民伤财"。
这时候,Go 语言的设计师们拍案而起:“我们要造一种更轻量的线程!” 于是,Goroutine (协程) 诞生了。它初始只要几 KB,切换成本极低。
这就带来了一个问题:操作系统只认识线程,不认识 Goroutine。谁来负责把成千上万个 Goroutine 分配给 CPU 跑呢?
这就需要一个"中间商" —— Go 运行时调度器 (Scheduler)。
 图示: Thread 与 Goroutine 的区别
图示: Thread 与 Goroutine 的区别
2. GMP 模型大揭秘
GMP 其实是三个角色的缩写:
- G (Goroutine):我们写的代码任务,也就是协程。
- M (Machine):工作线程(Thread),对应操作系统的真实线程。它是真正的干活人(搬砖工)。
- P (Processor):逻辑处理器(Context),可以理解为"调度上下文"或"资源"。它是包工头,负责管理 G,并把 G 交给 M 去执行。
形象的比喻
想象一个大型搬砖工地:
- G (砖头):待搬运的任务。
- M (工人):负责搬砖的劳动力。
- P (手推车):工人必须推着车才能搬砖(因为车里装着搬砖工具和任务清单)。
如果没有 P(手推车),M(工人)就不知道该干啥。
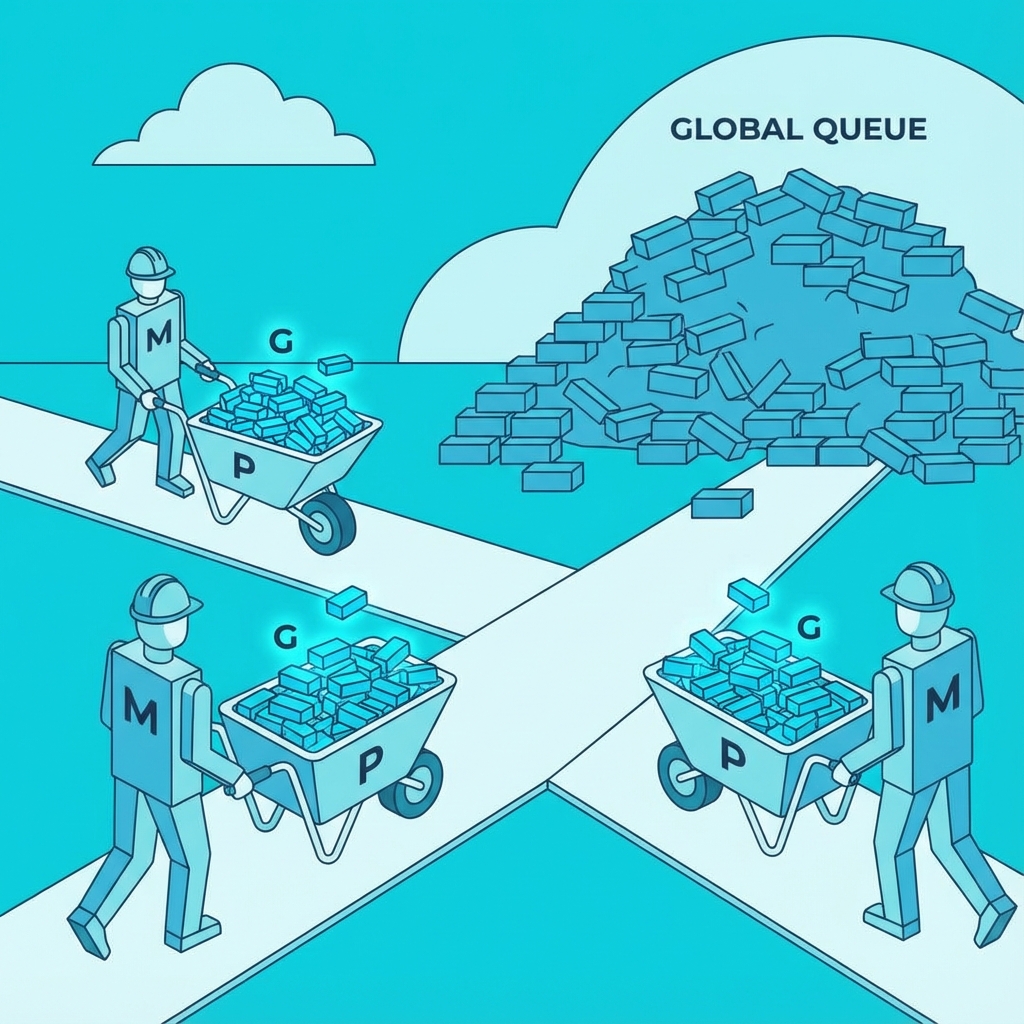 图示: GMP 模型示意图
图示: GMP 模型示意图
3. 调度器的核心策略
Go 调度器之所以高效,全靠以下几招"绝活"。
3.1 两个队列
P(手推车)不仅自己带着一小堆砖头(本地队列 Local Queue),工地上还有一个巨大的公共砖头堆(全局队列 Global Queue)。
- 优先吃独食:M(工人)推着 P(车)干活时,优先从 P 的本地队列里取 G(砖头)。这不需要加全局锁,速度飞快!
- 偶尔吃大锅饭:如果本地队列空了,M 就会去全局队列取 G(这时候要加锁,慢点但安全)。
3.2 WORK STEALING (工作窃取)
这是最骚的操作。
如果 M1(工人甲)手脚麻利,把自己车里和全局堆里的砖头都搬完了,而 M2(工人乙)还在呼哧呼哧地干活,M1 绝不会闲着抽烟。
M1 会悄悄跑到 M2 的车里,偷走一半的砖头(G)来干!
这就保证了所有 CPU 核心都一直忙碌,绝不摸鱼。

(图示:工人甲(M1)的车空了,正在从工人乙(M2)满满的车里"窃取"一部分砖头)
3.3 HAND OFF (移交)
如果 M1(工人甲)正在搬一块"超级重"的砖头(G 进行了系统调用,比如读文件,导致线程阻塞),M1 就被卡住了,动弹不得。
这时候,P(手推车)里的其他 G(砖头)咋办?
P 会果断抛弃 M1,带着剩下的 G 转移到另一个空闲的 M(或者新建一个 M)身上继续干活。
这就是 P 的无情剥离,保证了任务队列永远有 CPU 在跑。
4. Show Me The Code
我们用代码来验证一下 G 的轻量级。
我们尝试启动 100 万个 Goroutine,看看电脑会不会爆炸。
1package main
2
3import (
4 "fmt"
5 "runtime"
6 "sync"
7 "time"
8)
9
10func main() {
11 // 查看当前系统的 P 数量(通常等于 CPU 核数)
12 fmt.Println("GOMAXPROCS:", runtime.GOMAXPROCS(0))
13
14 var wg sync.WaitGroup
15 count := 1000 * 1000 // 100 万
16
17 start := time.Now()
18 for i := 0; i < count; i++ {
19 wg.Add(1)
20 go func() {
21 defer wg.Done()
22 // 假装做点复杂的数学运算
23 _ = 1 + 1
24 }()
25 }
26 wg.Wait()
27
28 fmt.Printf("Finished %d goroutines in %v\n", count, time.Since(start))
29}
运行结果(Mac M1 Pro):
1GOMAXPROCS: 10
2Finished 1000000 goroutines in 280ms
仅仅用了 280 毫秒!如果换成 Java 线程,这台电脑估计已经闻到焦味了。
老墨总结
GMP 调度器的 5 个关键点:
- G (Goroutine):轻量级协程,初始只要几 KB,是待执行的任务
- M (Machine):工作线程,对应操作系统的真实线程,是真正干活的
- P (Processor):逻辑处理器,管理 G 并把 G 交给 M 执行,是调度上下文
- Work Stealing:空闲的 M 会从其他 M 的队列偷取 G,保证 CPU 满负荷
- Hand Off:M 阻塞时,P 会转移到其他 M,保证任务队列不停滞
核心哲学:
- 复用线程:避免频繁创建、销毁 M
- 利用多核:通过 P 管理并发,让 M 并行执行
- 抢占式调度:防止某个 G 霸占 CPU 太久(Go 1.14 引入基于信号的抢占)
实战建议:
- 理解 GMP 模型,写出更高效的并发代码
- 合理设置 GOMAXPROCS(默认等于 CPU 核数) 验证
- 研究 Go 1.14 的抢占式调度,对比之前的协作式调度
本文代码示例:
- 百万 Goroutine 启动测试 长时间阻塞(会导致 M 阻塞)
- 使用 runtime.Gosched() 主动让出 CPU
- 监控 Goroutine 数量,避免无限制创建
理解了 GMP,你就理解了 Go 高并发的基石。下次面试官问你"协程为什么快",请把"工人推车搬砖"的故事讲给他听。
如果你的 Go 程序里的 G 全是死循环(比如 for {}),会发生什么?其他的 G 还有机会执行吗?(提示:搜索"GMP 抢占调度")欢迎评论区聊聊。
极客老墨,继续折腾!
练习题
- 运行百万 Goroutine 测试,观察内存和 CPU 使用情况
- 使用 runtime.GOMAXPROCS() 调整 P 的数量,观察性能变化
- 编写一个死循环 Goroutine,观察其他 Goroutine 是否能执行
- 使用 runtime.NumGoroutine() 监控 Goroutine 数量
- 理解 Work Stealing 机制,编写测试代码验证
- 研究 Go 1.14 的抢占式调度,对比之前的协作式调度
关注公众号:极客老墨
更多 AI 应用开发、工程实践和效率工具分享,欢迎扫码关注。
